�Դ�AMD���Fusion(�ھ�)�ĸ��NVIDIA�Ӵ������ƹ�GPUͨ�ü��㡢Intel���Ƚ�CPU��GPU������һ��֮��Ҿͻᷢ��CPU��GPU��û������������CPU��GPU֮������̫��Ĺ�ͬ��ʹ�����ǵĽ���Ҳ��ʼģ����������
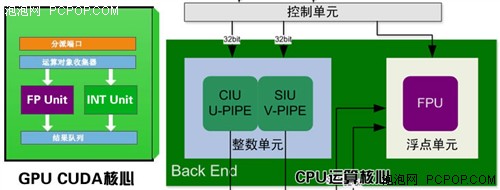
ϲ���о�ITӲ������������Ӧ��֪����CPU��GPU�������������㵥Ԫ���������㵥Ԫ��һ�����桢�������桢�ڴ�������ȵ�ģ����ɵģ����������ǵ�Ӧ���������ǽ�Ȼ��ͬ�ġ�
������GPUȡ��CPU���в��м����أ�����CPU����GPU��Ϊ����������������˵����Ȼ��������ģ����в���֧���ߡ�����ֻ�DZ�������������һ��״��ԭ����Ȼ������CPU��GPU�ļܹ�֮�У�ͨ�����ߺ����еķ������ᷢ��������˵��������ì�ܣ�����������Intel��AMD��NVIDIA�����ͷ�Ѿ���ɵĹ�ʶ�����������Ը��Բ�ͬ�ķ�ʽȥʵ����ͬ��Ŀ�ꡣ
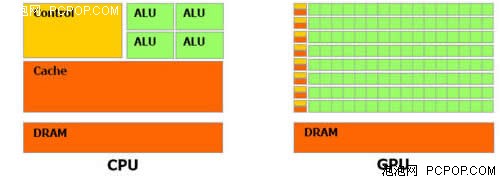
CPU��GPU������ṹ���ƣ������ص㲻ͬ
��ʵ�ϣ�CPU��GPU��������һ����Թ̶������ƣ����ո��ԵĹ켣�ڲ�ͣ�ķ�չ���ݱ䣬�����ڼ����ͼܹ��������źܶı���ϵĹ�ͬ�㣬��������Ҳ��Ϊ��ͬ��Ŀ�Ķ��ߵ���һ����ô��CPU��GPU����ײ��������ʲô���Ļ�δ���ķ�չ����ᳯ��δ��أ��������Ǿ�ͨ��CPU��GPU�ķ�չʷ���Ʋ�δ����ƷӦ�þ߱�ʲô����������
CPUƪ�����ϸ�������Э������
������������ʰһ��������Ҫ�����������ʡ���Э������������һ��оƬ�����ڼ���ϵͳ���������ض�����������Щ��Э��������Ҫ�����Ը������и������㡣
��
�����CPUֻ�ܽ����������㣬��������Ч�ʼ���
CPU�������������ǡ��Ӽ��˳�������ʵ���ϼ����ֻ���üӷ�������������Լ��̶�С����λ�ã����㣩���������㣬�����ܴ���С������Ը�������ֵ�����㣩������С������õ��Ƕ����ƵĿ�ѧ��������Ҳ���Ǹ�������ʾ����β������������λ��ռһλ��Ȼ���ٶ�������λβ������������Ч��λ�������䡣
��CPU����ʱ����������������Զ���������ӣ���Ϊ����β��Ҫ�������㣬����ҲҪ���룬������Ҫ��β���ͽ����ķ���λ�����д��������ԣ������CPU��û���������и������㣨8088/8086��80286��80386SX������Ҫ��������ʱ����CPUͨ������ģ����ʵ�֣����ԣ����и�������ʱ�ͻ����ܶࡣ
��
Э������������ר�Ŵ�����������

8086������������������8087
8086�ǵ���CPU�ı��棬��νX86�ܹ�Ҳ����ָ8086��������������ָ���ϵ��Ϊ���ֲ�8086�ڽ��и�������ʱ�IJ��㣬Intel��1980�������8087��ѧЭ������������ΪX86��ϵ�Ƴ��˵�һ�������ʽIEE754��8087�ṩ����������32/64bit����������̬�Ͷ������չ80bit�ڲ�֧Ԯ���Ľ���������֮���ȡ�����֮�⣬8087���ṩһ��80/17bit��װBCD (�����Ʊ���֮ʮ���ƣ���ʽ�Լ�16/32/64bit����������̬��

386������������������387
X87Э����������Լ60��ָ�������Ա�����е�ָ����ԡ�F����ͷ�������ı�8086��������ָ���������𣬾�����˵�������ADD/MUL��8087�ṩFADD/FMUL��
8087����1980�귢����Ȼ��80287��80387DX/SX��487SX��ȡ����
��
Э�����������Ͻ���CPU�ڲ�
������Э���������ǿ�ѡ�������������X86�������Ա�һ�㶼��ΪX87���һ���յIJ�ۣ�ֻ�е��û�ȷʵ����Ҫʱ�Ż�ר�Ź�����Ӧ��X87Э���������ȥ�������ٸ������㡣

486DX�ǵ�һ�������˸�������Э�������IJ�Ʒ���൱��486SX+487SX
����ʱ���ķ�չ��Խ��Խ��ij���Ҫ��ʹ�ø��߾��ȵĸ������㣬X87Э������������Ϊ�ر�Ʒ�����������칤����������֮��Intel��486һ����X86��X87��������һ�𣬸��������Ϊ��CPU��һ��������ܣ�������Ҫ��Խ��Խ��
Intel 486DX��Pentium֮���CPU���ں���Э��������AMD K5��K6֮���CPU���ڽ���Э�����������Դ˺�ͺ������˻��ἰЭ�������ĸ����ˡ�
CPUƪ����չָ����ٸ�������
��νX86�ܹ��Ĵ��������Dz�����Intel X86ָ��Ĵ�������X86ָ���Intel��˾Ϊ���һ��16λ������i8086��ר�ſ����ġ���IBM��1981�����Ƴ��ĵ�һ̨PC������ʹ�õĴ�����i8088��i8086�ļ棩Ҳ��ʹ�õ�X86ָ�������Ϊ����ǿ������ĸ�������������������X87��ѧЭ����������������X87ָ������Ǿͽ�������X86ָ���X87ָ��Ĵ�����ͳ��ΪX86�ܹ��Ĵ�������
X86����ָ������ˣ����ݴ��䡢�������㡢�����㡢��ָ�����ת�ơ�αָ��Ĵ�����λ����������ָ���������ָ���ʮ��������������Intel��AMD���漶��������X86ָ��Ļ����ϣ�Ϊ����������������������ܣ������ָ��Կ����µ�ָ������DZ���Ϊ��������չָ���
��չָ��ܹ�������CPU��ijЩ�ض�Ӧ���µ����ܣ����ý�塢3D����������ȣ�����Ƴ�����Э������������ͬ���ģ���Э��������Ҫ���Ӷ�������㵥Ԫ������չָ�ֻ��Ҫ�����µ�ָ����㷨���ɣ���������µ����㵥Ԫ��������Ҫ����֧�ֲ��ܷ��ӹ�Ч��
�� MMXָ�����ǿ��ý������
����MMX��Multi Media eXtension ��ý����չָ�ָ���Intel��˾��1996��Ϊ���µ�Pentiumϵ�д�������������һ���ý��ָ����ǿ������MMXָ��а�����57����ý��ָ�ͨ����Щָ�����һ���Դ���������ݣ��ڴ����������ʵ�ʴ���������ʱ�����ܹ������������������������������£����Եõ���ǿ�Ĵ������ܡ�
MMXָ��dz��ɹ�����֮�������ĸ���CPU��������Щָ����ݵ���Tom's Hardware���ԣ���ʹ������Pentium MMX 166MHzҲ��Pentium 200MHz��ͨ��Ҫ�졣

Intel Pentium With MMX���״�֧��MMX
���ǣ�MMXָ�������Ҳ�DZȽ����Եģ�MMXָ�������X86�ĸ�������ָ��ͬʱִ�У��������ܼ�ʽ�Ľ����л��ſ�������ִ�У���������һ�����ͻ��������ϵͳ�����ٶȵ��½���
�� 3DNow!ָ���
3DNow!ָ�����AMD��˾���Ƴ��ģ���ָ�Ӧ������SSEָ��֮ǰ�Ƴ��ģ����㷺������AMD��K6-2��K7ϵ�д������ϣ�ӵ��21����չָ�����������3DNow!��SSE�dz������ƣ����Ƕ�ӵ��8���µļĴ���������3DNow!��64λ�ģ���SSE��128λ��

AMD K62����3DNow��ָ� ����3DNow!��ֻ�ܴ洢�����������ݣ��������ĸ�����������SSE�IJ��ص�������ͬ��3DNow!ָ���Ҫ�����ά��ģ������任��Ч����Ⱦ��3D���ݵĴ���������Ӧ����������£����Դ������ߴ�������3D�������ܡ�AMD��˾��������Athlonϵ�д������Ͽ������µ�Enhanced 3DNow!ָ����µ���ǿָ��������52��������Ŀǰ��Ϊ���е�Athlon 64ϵ�д���������֧��3DNow��ָ��ġ�
��
SSEָ�����ǿ�����3D����
����SSE��Streaming SIMD Extension��SIMD��չָ�������д��������SIMD��Ϊ����ΪSingle Istruction Multiple Data����ָ������ݣ�������SSEָ�Ҳ�е�ָ�����������չ����ָ�����������Intel��Pentium IIIϵ�д���������ʵ��Pentium III�Ƴ�֮ǰ��Intel������Ѿ�й©������KNI��Katmai New Instruction��ָ�����Ϣ�����KNIָ�Ҳ����SSEָ���ǰ������ʱҲ�в��ٵ�ý�彫��ָ���֮ΪMMX2ָ�������Intel����ȴ��û�з����й�MMX2ָ�����Ϣ��

����3��ʽ����SSEָ�
���������Intel�Ƴ�Pentium III��������ʱ��SSEָ�Ҳ����ˮ��ʯ����SSEָ���Ϊ��ߴ������������ܶ���������չָ���������70��ָ����а������3Dͼ������Ч�ʵ�50��SIMD��������ָ�12��MMX����������ǿָ�8���Ż��ڴ��е��������ݿ鴫��ָ���������Щָ��Ե�ʱ���е�ͼ�������������㡢3D���㡢��ý�崦�����ڶ��ý���Ӧ��������ȫ�����������á�SSEָ����AMD��˾��3DNow!ָ��˴˻������ݣ���SSE������3DNow!�еľ��ֹ��ܣ�ֻ��ʵ�ֵķ�����ͬ���ѡ�SSEҲ���¼���MMXָ�������ͨ��SIMD�͵�ʱ�����ڲ��д������������������Ч����߸��������ٶȡ�
�� SSE2ָ�����һ���Ż���������
������Pentium III������ʱ��SSEָ����Ѿ��������˴��������ڲ�������Ϊ����ԭ��һֱû�еõ���ֵķ�չ��ֱ��Pentium 4����֮������Ա����ʹ��SSEָ��֮����ִ�����ܽ��õ����������������Intel����SSE�Ļ������Ƴ��˸��Ƚ���SSE2ָ���

����4�����ͼ�����SSE2ָ���AMDֱ��Athlon64�ż���SSE2��
����SSE2������144��ָ������������飺SSE���ֺ�MMX���֡�SSE������Ҫ����������������MMX������ר�ż���������SSE2�ļĴ���������MMX�Ĵ������������Ĵ����洢����Ҳ��������������ָ����ٶȱ��ֲ��������£�ͨ��SSE2�Ż���ij�������������ٶ�Ҳ�ܹ��������������SSE2ָ���MMXָ�����ݣ���˱�MMX�Ż����ij�������ױ�SSE2�ٽ��и����ε��Ż����ﵽ���õ�����Ч����
SSE2���ڴ����������ܵ�������ʮ�����Եģ���Ȼ��ͬƵ�ʵ�����£�Pentium 4�����ܲ���Athlon XP��������Athlon XP��֧��SSE2�����Ծ���SSE2�Ż���ij���Pentium 4�������ٶ�Ҫ���Ը���Athlon XP����AMD����Ҳע�����һ�����������K-8ϵ�д������У�������SSE2ָ���
�� SSE3ָ�����ǿ�������ݴ�������
����SSE3ָ����Ŀǰ��ģ��С��ָ�����ֻ��13��ָ���������Ϊ���Ӧ�˲㣬�ֱ�Ϊ���ݴ���������ݴ���������������Ż�������߳�������ǿ������֣����г��߳�������ǿ��һ��ȫ�µ�ָ��������������������ij��̵߳Ĵ��������������˳��̵߳����ݴ������̣�ʹ�������ܹ����ӿ��ٵĽ��в������ݴ�����

SSE3��13����ָ�����ҪĿ���ǸĽ��߳�ͬ�����ض�Ӧ�ó�����������ý�����Ϸ����Щ����ָ��ǿ���˴������ڸ���ת���������������㷨����Ƶ���롢SIMD����Ĵ��������Լ��߳�ͬ�����������ı��֣����մﵽ������ý�����Ϸ���ܵ�Ŀ�ġ�
Intel�Ǵ�Prescott���ĵ�Pentium 4��ʼ֧��SSE3ָ��ģ���AMD���Ǵ�2005���°���Troy���ĵ�Opteron��ʼ��֧��SSE3�ġ�������Ҫע����ǣ�AMD��֧�ֵ�SSE3��Intel��SSE3������ȫ��ͬ����Ҫ��ɾ�������Intel���̼߳����Ż��IJ���ָ�
��
SSSE3(SSE3S)ָ�����ǿ��ý��ͼ��ͼ����
SSSE3��Supplemental Streaming SIMD Extensions 3����Intel������SSE3ָ������䣬��ʹ���µĺ�������ΪSSSE3�Ƚ����Ǽ�ǿ���SSE3���������Ƴ�SSSE3֮ǰ��SSE4�Ķ������ױ��������ڹ���Intel��Core�ܹ�֮ʱ��SSSE3������Xeon 5100��Intel Core 2�ƶ����������ʹ������ϡ�

65nm Core 2 Duo����SSSE3ָ�
SSSE3������16���µIJ�ͬ��SSE3��ָ�ÿһ�����ܹ�������64λ��MMX�Ĵ�������128λXMM�Ĵ���֮�С���ˣ���ЩIntel���ļ���ʾ��32����ָ�SSSE3ָ���ǿ��CPU�Ķ�ý�塢ͼ��ͼ��������ý����롢���������Internet�ȷ���Ĵ���������
��
SSE4.1ָ�����������������㣬�Ż�CPU��GPU���ݹ���
SSE4.1ָ�����Ϊ��2001������Intel����Ҫ��ָ���չ������54��ָ�Intel��Penryn�������м����˶�SSE4.1��֧�֣���������47����ָ�������Ķ�ý�崦�������õ����70%��������SSE4������6�������͵������ָ�֧�ֵ����ȡ�˫���ȸ������㼰���������������IEEE 754ָ�� (Nearest, -Inf, +Inf, and Truncate) ������ת����·��ģʽ��������������Щ�ı佫����Ϸ��3D��������Ӧ������Ҫ���塣
���⣬SSE4���봮��ʽ����ָ��������ͼ��֡�������Ķ�ȡ����Ƶ���������Ͽɻ�ȡ�����Ŀ�ȡ�����У���ÿ�ζ�ȡ64Bit����8Bit�����ɱ�������ʱ�������ڣ���ָ�����ɴ���8���Ķ�ȡƵ��Ч��������������Ѷ�����������Լ�GPU��CPU֮��Ĺ�������Ӧ�ã��������Ե�Ч��������
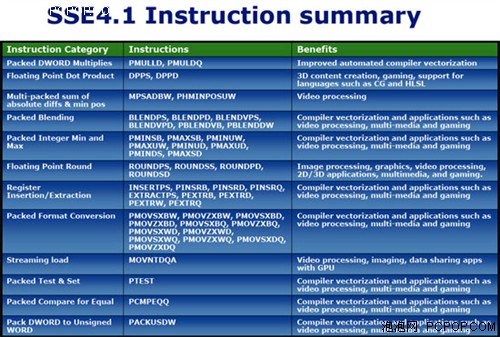
45nm Core 2 Duo����SSE4.1ָ�
����SSE4ָ���45nm Penryn������������2����ͬ��32Bit���������˷����㵥Ԫ��������8λ����(Unsigned)��Сֵ�����ֵ���㣬�Լ�16Bit��32Bit�з��� (Signed) ���㡣�����֧��SSE4ָ�������ʱ��������Ч�ĸ��Ʊ�����Ч�ʼ���������������������ȴ��������������ͬʱ��SSE4�������롢��ȡ��Ѱ�ҡ���ɢ���粽���ؼ��洢�ȶ����������������һ��ר�š�
�� SSE4.2ָ����Ż�XML�ͽ���ʽӦ������
��Nehalem�ܹ���Core i7�������У�SSE4.2ָ������룬������STTNI���ַ����ı���ָ���ATA������Ӧ�õļ������������Ż�ָ�STTNI���������������ָ�STTNIָ����Զ�����16λ�����ݽ���ƥ��������Լ�����XML������������ܡ�Intel��ʾ����ָ�������XML��������ȡ��3.8��������������
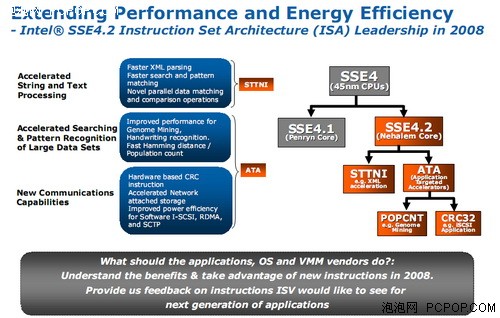
ATA��������У���CRC32ָ�����Դ�������з�0λ������POPCNTָ��Լ����ڴ����64λ���������SIMDָ�CRC32ָ�����ȡ���ϲ�����Э���о����õ���ѭ������У�飬Intel��ʾ����ٱȿ��Դﵽ6.5~18.6����POPCNT���������DNA������ԡ�����ʶ��Ȱ��������ݼ��н���ģʽʶ��������Ȳ�����Ӧ�ó������ܡ�
CPUƪ������Ƭ�϶�������
����Ļ��������������������ݵĴ��䡣�ڵ��Ե��У������ڴ��Ӳ�̱������ٶȽ���������Ҫһ�����Լ���ָ��ִ�к�����Ԥȡ�Ļ������������ʱ������൱�ڲ�����ļ��������������ߵ������Dz��ϵ��ڱ仯�ġ�
http://www.yourdictionary.com/images/computer/SWFCACH2.SWF
��������ú�ԭ��
һ������(L1)��������CPUоƬ�ڲ���һ���洢������������(L2)�ǵ�2�顰�����������(Staging Areas)�������ô����Ǹ�L1ι���ݡ�L2����������CPU֮�У�Ҳ������MCP(Multichip Package Module)���һ������оƬ�У����������������ϵ�һ������洢оƬ�
���͵ģ�����һ����SRAM(Static RAM����ֹ����洢��������Ҫˢ�µ�·���ܱ������ڲ��洢������)�������ڴ�ͨ����DRAM(Dynamic RAM����̬����洢������Ҫˢ�µ�·)��SRAM�dz����ľ���ܡ��ɱ��߰������������������ܴ���������CPU����û�л���ģ������ſ�ʼ���뻺��оƬ��
��
���������ϵĶ������棨���������������ϣ�

Intel 430FXоƬ�M��Socket 5���弰256KB���ö�������
��ǰ��CPUһֱ����Socket�ӿ���ƣ����Ե�ʱ�ļ�����ֱ��ʽ���������CPU������SRAM����оƬ��ֻ�ܽ�SRAM����չ������ʽ���������ϻ���ֱ�������������ϡ��˺�������Ʒ��Intel��AMD������Slot��װ��ʽ����SRAMоƬ��CPU���Ķ���������Slot PCB���棬Ȼ���ٲ��������ϣ�����SRAM�����������ʽ��Ϊ��CPU����ȱ�ٵ�һ���֡�
��
������CPU�ϵĶ�������

����һ�ź��Ĵ���Ϊ��Klamath������350nm���յ�Pentium��������CPU+SRAM�Ľṹ��Slot 1�ӿڡ�����ȥ�Dz����е������ڵ�GPU+DRAM�Դ档ʵ����������ֻ����CPU��SRAM������һ�𣬶���������Ȼ�Ժ���Ƶ��һ���������͵��ٶ����У����ܲ������롣
��
����ˮ��ʽ�Ķ�������

Pentium Pro��Intel P5 ����Pentium�����죬��1995��11����Socket 8��װ��ʽ�Ƴ�����������ɫ�Dz�����˫оƬ��װ��ʽ��CPU��L2�Ǹ��Զ����ģ�Ƭ�ϣ�Onchip��L2�ĺô��ǿ����������ں���ͬ��Ƶ�����У������������ȥʹ�������Ͻ����ٶȵ�L2���Ӷ�Ϊ������ִ�С������µĴ����ڴ泬���ṩ�˽ݾ���ֱ�����������ܡ�
Pentium Pro��L1��L2ͬʱ�����CPU���ڲ�����Pentium Pro������ϴ��Pentium II�ְ�L2 Cache����CPU�ں�֮��ĺں����������ΪL2���ﵽ�������ͬ��Ƶ�ʣ���˻��Ƿ���ʽ�Ƚ����һ�㡣
��
���Ͻ�CPU�ڲ��Ķ�������
Pentium Pro�����ǵ�һ�������˶��������CPU�������ǵ�һ��32bit CPU�������������������ݵ�ʱ������16bit���������Pentium Pro���ߺѣ�����λ�ڸ߶˷������г�����û�еõ��㷺�Ͽɡ��˺�Intel�ַ�����Pentium II XEON��ͬ��������Ƭ��ȫ�ٶ������棬�ڵ�ʱȫ�ٶ�������ʹ����Ÿ��ߵ����ܡ�
Pentium Pro��Pentium II XEON�������ò�Ʒ����˹�ע�Ȳ����ߣ���Pentium IIȥ������SRAM�IJ�Ʒ���״ε���Celeron��������Ȼ���۸�ܵ�����������L2����Ϊ0�����������ʧҲ�dz����ء�Ϊ�ˣ�Intel�Ƴ��˵ڶ���Celeron 300A��Celeron 333����������ص����ڴ�����оƬ�ڼ�����128KB�������ٻ��棬��������Ȼ��Pentium II��512KB�ٺܶ࣬��������Ķ���������CPU�ڲ�����ȫ�ٵ�Ƭ�ϻ��棬��Pentium�Ķ�������Ƶ��ֻ�к��ĵ�һ�롣������ȫ�ٵĶ������������Celeron�ʵĸı䣬����ĸ�����������������ܣ���Ϊ��ʱ�г������ֿ��ȵ�һ�������Ʒ��
�״γ�����������
����ʱ��AMDҲ��һ����Ʒ��ͬ������Ϊ������ȫ�ٶ�������������ܲ����ʵķ�Ծ������ңң������ͬ��Intel��������������K6-II��K6-III��
K6-II��K6-IIIʹ�õ���Socket 7��ۣ������ܱ�Intel������Pentium 3��Ҫǿ��Ϊʲô����Ϊ��K6-III CPU���ڽ���256KB�Ķ������棬�������������ϻ����ٲ�2M������SRAM������������ʹ�ã���ʱ�����ܱ�Pentium II�����˽ϴ�IJ�࣬������۸Ƚ�ʵ�ݡ�
��
����������������Ȼ�����ö������棬����ȫ������ȫ�ٻ���
���������������źܶ��˾ͱȽ���Ϥ�ˣ�����Ӧ�ÿ���˵��CPU�Ľ����ִ�ʷ�ˣ�������������������֮����Ȼʹ�õ�Slot����ʽ��װ������������Ȼ������ʽ������Ƶ��ֻ�к����ٶȵ�һ�룬�����ܵ������ơ�


����Slot 1��Slot A�ӿڵ�Pentium III��Athlon
���칤�ոĽ�֮��Intel��AMD��̰�L2��������CPU�ڲ�����Ϊ��һ��CPU���ģ��Դ��ϲ���ּ���Socket��װ��ʽ���֣�ȫ�ٵ�L2�ñ��������������ܶ�����������


Socket 370��Socket A�ӿڵ�Pentium III��Athlon
Pentium III��Athlon����1GHz��ص�Ƶ�ʴ�ս������Intel��ΪPentium III 1.13GHz BUG������ܱ�����������Ĺؼ��������õĶ���������������1GHz���ϵij���Ƶ���£��Ӷ���������Ԥ�ϵĴ���
CPUƪ�������ڴ�������ͱ���
CPU��������֮���Զ�CPU����Ӱ���ش�����Ϊ�ڴ���ӳٽϴ���̫С�����㲻��CPU�ܼ������ݽ�������Ҫ����Ҫ����������תվ���������֧�֡��ڶ������汻CPU����֮���������ڴ���Ȼ���������ϵ�CPU����ģ���ô��β��ܽ�һ���Ż��ڴ������أ�
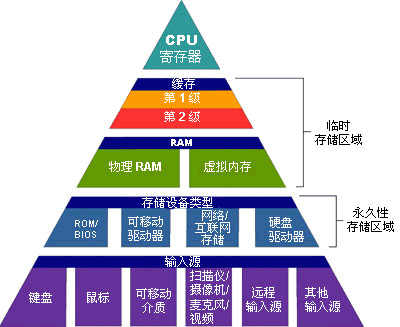
������CPU���ڴ�֮���ͨ����ͨ�����źͽ��еģ�ȷ��˵�DZ��ŵ��е��ڴ����������������ϵͳ��֧���ڴ��������Ƶ�ʺ��ӳ١�Ϊ�˾����ܵ���СCPU�����ڴ��ʱ�䣬��ȻCPU�����ڴ�����������Ч�ķ�����
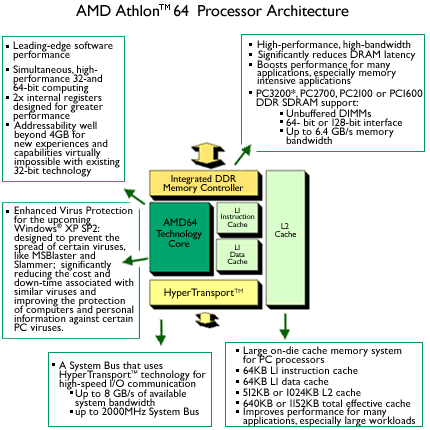
AMD���Ƚ��ڴ��������������CPU���У�Athlon 64��ʱ���IJ�Ʒ��Ϊ��һ�����䣬��Ȼ��ɹ���ԭ��������Ϊ�������ڴ�������������ǵ�һ��64bit X86����������һ��ʹ���˵�Ե�ĸ��ٵ��ӳ�HT���ߡ�AMD���һ���Ⱦ������꣬Intelֱ��Core i7ʱ�����������ڴ��������
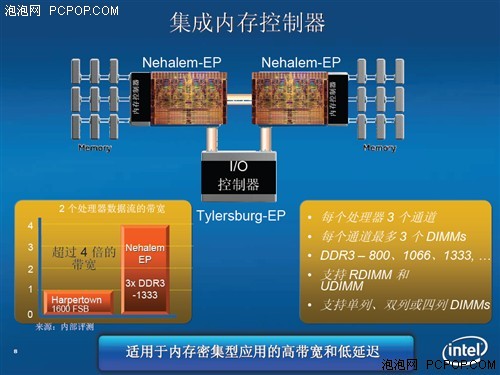
AMD����ΪAthlon 64�����������˵�ͨ��DDR��˫ͨ��DDR�����ڴ���������ֱ��Ӧ754��939�ӿڣ��˺���������˫ͨ��DDR2��DDR3�ڴ����������Intel�Ǻ����߾��ϣ�ֱ����������ͨ��DDR3�ڴ���������еͶ˲�ƷҲ������˫ͨ��DDR3�ڴ���������ֱ��Ӧ1366��1156�ӿڡ��������ڴ�ƿ��֮���Core i3/i5/i7���������ܸ���һ��¥�����������ͬ��AMD��Ʒ��
CPUƪ������ʽ��������/��������
��Ƶ���ܵ�Pentium 4��Pentium D���ֿ�Athlon 64��Athlon 64 X2��������ͬʱ��IntelҲ�������з���һ��Core�������ܹ���ȫ�µ�Core 2 Duo��Ȼû�������ڴ����������ƾ���Ч�ʡ��Ͳ㼶��ˮ�ߺ��ںϴ����Ƚ�������ָ��ܹ���Core 2 Duoһ�ٻ���Athlon 64 X2��Ϊ�µ�����֮����
��Ȼ��Intel��������һ����Եļ���Ҳ��Core 2 Duoһ��֮������������ֵ����ƣ�������Intel Advanced Smart Cache�������ܻ��漼���������������Ƕ�Ŵ��������Ĺ������������棬ͨ������Ϊ����ʽ�������������档
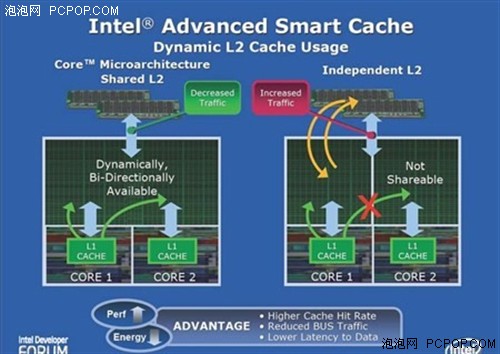
��ͳ��˫�������ÿ�������ĺ��Ķ����Լ���L2����Intel Core�ܹ�����ͨ�������ڲ���Shared Bus Router������ͬ��L2����CPU 1������Ϻ�ѽ������L2ʱ��CPU 0���ͨ��Shared Bus Router��ȡCPU 1���ڹ���L2�����ϣ�������Ͷ�ȡ�ϵ��ӳٲ�����ʹ��FSB������ͬʱ����L2 & DCU Data Pre-fetchers��Deeper Write output����洢������������˻���������ʡ�
��AMD K8˫����L2�ܹ���ȣ�CPU 0��Ҫ��ȡCPU 2 L2������ʱ��������Ҫ��ϵͳ���߷�������ͨ��Crossbar Switch�Ͱ�ȡ�����ϣ���CPU 0���ֶ�ȡ�Լ���L2û����Ҫ�����ݲŻ�Ҫ���ȡCPU 1��L2���ϣ������ͬ��CPU 0��L3��������ʽ��L2���ȴû��������Ҫ��
Smart Cache�ܹ����кܶͬ�ĺô������統���ź��Ĺ�������ƽ��ʱ���������L2��˫���ļܹ��л����������һ�ź��Ĺ��������٣�L2û�б���Ч��Ӧ�ã�����һ�ź��ĵ�L2ȴ���������أ�L2����û��Ӧ������Ҫ��ȡϵͳ�ڴ棬ֵ��ע�����������������һ�ź��ĵ�L2�ռ䣬��SmartCache��L2�ǹ��õĶ�û��������⡣
����ʽL2�����ܹ��������ź���֮���ȡ�������ݵ��ӳ١�������������ʣ����һ�����Ч����������ʣ��������ʽ�������ظ����ݵĿ��ܣ�������ߵĻ���������Intel�ϴ���Core 2 Duo��Core 2 Quad���������ܷ��沢�����AMD��Phenom IIϵ�д����������й���ʽ����������ƹ�����û��
��
����ʽ���������ѳ�Ϊ������
����ʽ���������Ȼӵ��������ƣ�����Ҫ�Դ�ͳCPU�ܹ����д��������˫���Ļ������ס�����ľͱȽ��鷳�ˣ�����Ĵ�ȡ���ƶ���Ҫ��ȫ������ơ����AMD�����辶���ڱ������ж������治�������£�ֱ���������������������棬�Ӷ�Ϊ����ṩЭͬ����ĸ����ݴ����ݲֿ⡣

AMD������Phenom�ĺ˴������Ͳ����˹���ʽ����������ƣ�ÿ�ź��ĵ�һ�����汣�ֲ��䣬�������涼�Ƕ�����512KB����������Ϊһ��ʽ��2MB��������Phenom II����45nm����ʹ�ô������ܹ����ϸ��������Ļ��棬����L3������6MB�����������dz����ԡ�
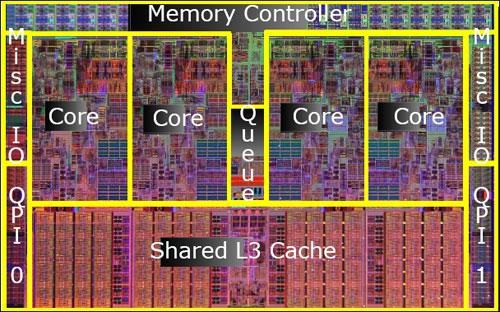
Core i7 Dieʾ��ͼ
Intel��Core 2 Quad֮��Ҳ������ȫ�µ�ԭ���ĺ˲�Ʒ���˴�Intel�������Ƚ�������һ�壬�����������ڴ�����������������˱�AMD HT���Ƚ���QPI���ߣ��������˹���ʽ�������棬�����ߴ�8MB����Phenom II����2MB��
���ڵͶ˵�˫��Core i3/i5��������IntelΪ�˱��ּܹ�ͳһ��Ҳ������Core 2����Ĺ�������������ƣ�ÿ�ź��Ľ���256KB�Ķ���L2������ֲ����4M������L3����Ȼ�ܻ�����������E8X00ϵ�е�6MB L2���������ϻ���ȡ���˳���Ľ�����
�˺�32nm���յ�����ʹ��Intel�����ڵ�һоƬ֮�м��ɸ���ĺ��ĺ���Ļ��棬�������ǿ���i7-980Xӵ���������������Լ��ߴ�12MB��L3�����ܸ���һ��¥������̾Ϊ��ֹ��
GPUƪ������VCD/DVD/HD/BD��ѹ��
���˽���CPU�ķ�չ����֮��������������GPU�ķ�չ���̣���ʵGPU�ܶ��ش�Ľ�����CPU�ļ����ܹ������ơ������ʼ���ǽ����˹��ϵ�CPUЭ�������������ٽ���һ���������IJ�Ʒ������ѹ�����������ϵ����Ӧ�üǵá�
ʮ����ǰ�����Ե�CPU��Ƶ�ܵͣ��Կ�Ҳ��Ϊ2D��ʾ�ã���VCD�����ʱ�ö���ԣ���ƵΪ100MHz���£���������ѹ�ķ�ʽ��VCDӰƬ���������в�����!

ISA�ӿڵ�VCD��ѹ��
��ʱ��VCD��ѹ���ͳ����ˣ��˿�����ר�õĽ��봦�����ͻ��棬ʵ�ֶ�VCD��Ӳ���룬����ҪCPU���н������㣬���ԣ���ʹ��386�ĵ�����Ҳ���Կ�VCD�ˡ�

PCI�ӿڵ�DVD��ѹ��
����Կ�������3Dʱ����������֧��VCD��MPEG���룬����CPU����ƵҲ�����ˣ�����CPU������Կ��������붼��������������Ƶ������VCD��ѹ�����˳����г���
��DVDʱ�����ٺֱ�����ߺܶ࣬���ұ���������MPEG2������CPU���Կ��Ľ�������������µ�Ҫ��ʱ������һЩDVD��ѹ�������ϻ�������֮�ã�������CPU���»�������Ƶ�������������ܴ�DVD��ѹ��Ҳ��꼻�һ�֣�����ʧ�����ˡ�

�����Ѿ���1080pȫ����ʱ���ˣ�������Ƶ������Ȼ�Ƿdz�����CPU��Դ��Ӧ��֮һ�����Ǽ���ǰNVIDIA��ATI����GPU����������ר�õ���Ƶ����ģ�飬NVIDIA�����ΪVP��Video Processor����Ƶ����������ATI�����ΪUVD��Unified Video Decoder��ͨ����Ƶ������������Ӧ�ļ���������PureVideo��AVIVO��

Ӳ���뼸��������CPU��GPU����Դ����������Ƶʱ�ӽ��ڴ���״̬
��ȻVP��UVD������������GPU�ڲ���ʵ�������ǵ�ԭ���������뵱���Э������/��ѹ��оƬû��ʵ�������𣬶���Ϊ�˼���/�ֵ���������ij���ض��������NVIDIA��ATI��GPUӲ���뼼�����ܹ�֧�ָ߷ֱ��ʡ������ʡ��ಿӰƬͬʱ���ţ����ܺͼ����Զ��ܳ�ɫ��
�����CPU�������Ѿ��൱ǿ���ˣ����������Ƶ��ֱ���ɼ���죬��Ҫ��Ч�ʵĻ�����Ȼ��GPUӲ�������ʤһ�ר��ģ�����������Դ���٣��������ķ��ȸ�С������ֳ��豸���ƶ��豸��ʹ��Ӳ�����룬���������CPU�����GPUӲ�������ν�ˡ�
GPUƪ��ShaderModelָ��������뷢չ
��ָһ�㣬��GPU��������˫�������Ƴ���ʮ����Ʒ��ÿһ����Ʒ֮��ĶԾ�������������Ķ����ѣ���������ʵ�ս����������DirectX API�汾����ʱ���֣���������˵����DirectX������GPU�ķ�չ��������DirectX�汾����ʱ�ĺ������ݣ�ǡǡ��������ShaderModel���У�

ShaderModel 1.0 �� DirectX 8.0
ShaderModel 2.0 �� DirectX 9.0b
ShaderModel 3.0 �� DirectX 9.0c
ShaderModel 4.0 �� DirectX 10
ShaderModel 5.0 �� DirectX 11
Shader����Ϊ��Ⱦ����ɫ����һ���ܹ����3D������в���������GPU��ִ�еij���ShaderModel�ĺ�����ǡ��Ż���Ⱦ����ģʽ�������ǿ������������GPU����Ⱦָ���
�߰汾��ShaderModel��һ�����������еͰ汾���Եij�������һЩָ���������Ľ���ͬʱ����������һЩ�µļ���������˵��GPU��ShaderModelָ���CPU��MMX��SSE����չָ�ʮ�����ơ�
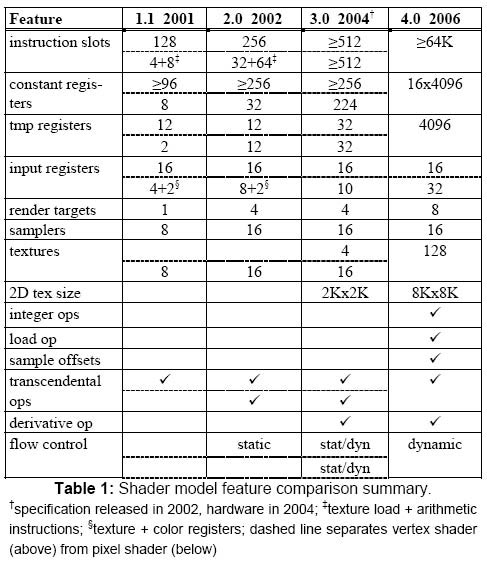
����ShaderModelָ���������Ľ���GPU�Ĵ�����Դ�ͼ��㾫�����վ��������Ǿ���������Ⱦ�����Ӿ�����ͼ���Ҳ�����������ܵĴ���½���������������汾��������ָ���û�д���̫���µ���Ч����ȴƾ��������㷨���������ܣ��Ƿ�֧��DX10.1��ShaderModel 4.1��������Ϸ������û�в�𣬵��ٶȾͺ������ˡ�
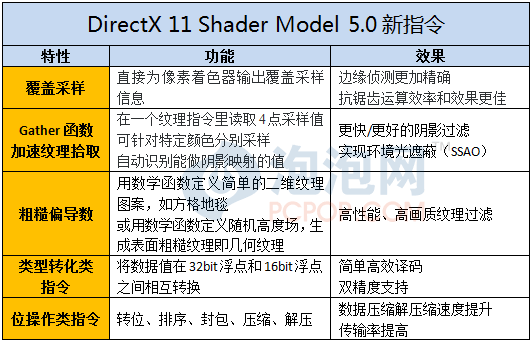
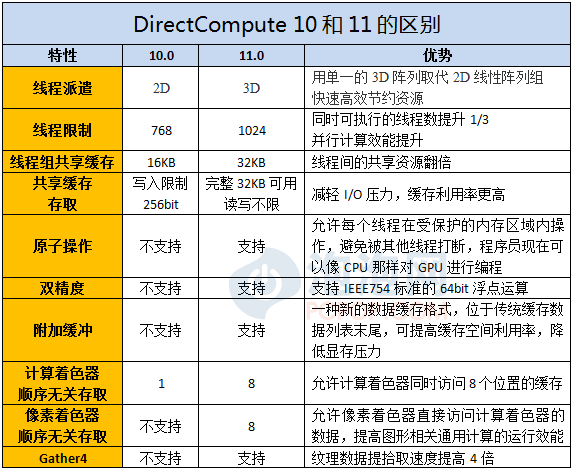
���⣬DX11�еĹؼ�����DirectComputeͨ�ü��㼼������ͨ������ShaderModel 5.0�е���ָ������GPU������Ч�ʣ��ܶ����DirectCompute������ͼ�κ�����Ⱦ��ЧҲ��Ҫ�õ�SM5.0ָ���������ܡ�
GPUƪ��������˫��/�ĺ�GPU
�������Ķദ����ϵͳ�����ڵ�˫�ˡ��ĺˡ����ˣ�CPUֻ���������Ӻ����������������ܡ���GPU��һ��ʼ������Ϊ������Ⱦ�Ĺ���ʽ�ܹ���GPU���ܵ�ǿ����Ҫ���ǿ�˭�Ĺ��ߡ����������������ࡣ
����˫�Կ��������Կ�Ҳ��Ϊ����������Ϸ���ܵ�һ��;����ͨ��SLI��CrossFire�����ܹ�������3D���ܱ���������˫���ĵ��Կ���ΪNVIDIA��AMD˫������3D�������߱�����ɱ��ﵣ����������콢���Կ���������˫������Ƶġ�
����CPU��оƬ���϶���ĵ���Ʋ�ͬ���Կ�һ���ǵ�����GPU��ƣ������е�һGPU�������ƣ���ΪGPU����������ƿ����Ҫ�������칤�գ�ֻҪ���ո����ϣ���ô���Ǿ���������GPU�ڲ�ֲ�뾡���ܶ������������
��
˫������Ƶ�Cypress���ģ�
����GPU�ܹ��IJ��ģ�����������������Ҫ����ģ�ȷ��˵���Լ�����ģ�������������ܴ�������������ܡ�����������������������֮����ι���������Ӵ�Ĺ�ģ����������ģ��Э��������Ϊ�µ����⡣

RV870��˫����ģ�����
ATI RV870���������������ڵ����к��Ĺ��RV770����һ����ATIѡ���ˡ�˫���ġ���ƣ������Dz��ŷ�������RV770���ģ�������װ�������ڲ����������Rasterizer����դ������Hierarchial-Z���༶Z����ģ�飩��������˫�����Ĺ���θ�ڡ�
��
�ĺ�����Ƶ�GF100���ģ�

GF100���Կ������ĺ������
���˵Cypress��˫������ƵĻ�����ôGF100�������������־��ǡ��ĺ��ġ���ƣ���ΪGF100ӵ���ĸ�GPC��ͼ�δ�������Ⱥ��ģ�飬ÿ��GPC�ڲ�����һ��������Raster Engine����դ�����棩������������������GPU����һ��Raster Engine��
����֪��RV870��Rasterizer��Hierarchial-Z˫�ݵģ���GF100�����ķݵģ���Ȼ����������ͬ����������ͬ�ġ�

GF100��ÿ��GPC�����Կ�����һ���Ը������GPU
GF100���ĸ�GPC����ȫ��ͬ�ģ�ÿ��GPC�ڲ�������������Ҫ��ͼ�δ�����Ԫ���������˶��㡢���Ρ���դ�������Լ����ش�����Դ�ľ��⼯�ϡ�����ROP�������⣬GPC���Ա�������һ���Ը������GPU������˵GF100����һ���ĺ��ĵ�GPU��
��
ΪʲôGPUҲ����Ƴɶ���ģ�
GPU��������һ�Ų��д�������ÿһ��������������һ�����������㵥Ԫ��ATI��NVIDIA˫����һ�ν�GPU��Ƴ�Ϊ����ķ�����������Ϊ����������������������������Դ������Ϊ�˸��õĹ����Ϳ����Ӵ��ģ����������������ֵ��������ǵĴ����������Ա��ڲ�ͬ��Ӧ�û����·��ӳ���ǿЧ�ܡ�
��˵������������������GPU�ĸ���������������GPU���˵�������ѧ�����⣬��Ҫ������ͬ���͵������Ӵ��������������Ϊ������������飬ÿ�����鶼���ר�õĿ�������������ģ�飬�⽫����Ч��ƽ���������ģ�����Դ�����ʡ�
GPUƪ����̬����ʽһ����������
GPU�ڲ�ӵ�кܶ������͵Ļ��棬��ͬ�Ļ��涼�и����������;��������������ݣ�����ȫ��ͬ��CPU�ڲ�L1��L2��L3�����IJ㼶��ϵ��
��
Cypress��һ�����棺�̶����ܡ��̶�������ר�û���
AMD��Cypress�����ڲ������������ǰ���SIMD����ָ��������������ֵģ�ÿ��SIMD�����ڲ�������80��������������Щ��������ӵ�ж�����������Ԫ��һ�����棨L1���Լ��������ݹ������棨Local Data Share����

Ϊ������DX11��DirectCompute 11��Ҫ��AMD�����˱������ݹ�������Ĵ�С(Local Data Share��LDS)�������ﵽ��32KB����RV770��������LDS����ͬһ���߳���(Thread Group)�е��̹߳������ݡ�����ͼ�����ǿ��Կ�����ÿһ��SIMD����һ��LDS����ͬ��SIMD�Dz��ܹ���LDS�ģ������������ͬһ���߳�����̶߳��ᱻ�̵߳��������͵�ͬһ��SIMD��ִ�С�
�����ͬ��SIMD�ϵ��߳�Ҫ�������ݣ���Ҫ�õ�ȫ�����ݹ�������(Global Data Share,GDS)����Cypress�У�GDS������Ҳ�����ˣ��ﵽ64KB����ĿǰΪֹ�����Ƕ�GDS���˽���Ȼ���ޣ���LDS��ͬ����û��ָ������ʽ�IJ���GDS����Beyond3D����Ϣ����δ����OpenCL��չ�п��ܻ��ṩ��GDS�ķ��ʣ�ĿǰGDSֻ�Ա������ɼ���
��
GF100��һ�����棺�ɶ�̬���������Ķ�����ܻ���
������GPU����û��һ������ģ�ֻ��һ���������棬��Ϊ��Щ��������ͨ�ü��������ڴ洢�������ݣ�ֻ����������������ʱ�ݴ�����������GF100���У�NVIDIA�״�����������һ�����ٻ��棬���һ��ɱ���̬�Ļ���Ϊ�������档
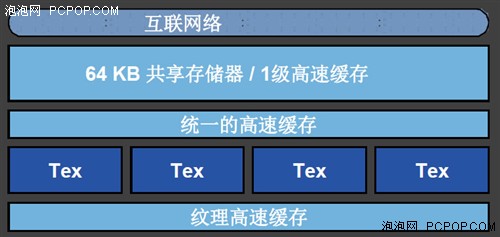
��GF100 GPU�У�ÿ��SM����ӵ��ר�õ����������⣬��ӵ��64KB������Ƭ�ϻ��棬�ⲿ�ֻ��������Ϊ16KB��һ������+48KB�������棬������48KBһ������+16KB�������档���ֻ��ַ�ʽ��ȫ�Ƕ�ִ̬�еģ�һ��ʱ������֮����Զ�����������Ҫ��ʱ�л�������Ҫ����������Ԥ��
һ�������빲�������ǻ����ģ����������ܹ�Ϊ��ȷ�綨��ȡ���ݵ��㷨������ȡ�ٶȣ���һ���������ܹ�ΪһЩ��������㷨�����洢����ȡ�ٶȡ�����Щ�������㷨�У����Ȳ���֪�����ݵ�ַ��
����ͼ����Ⱦ��˵���ظ����߹̶������ݱȽ϶࣬���һ���ǻ���48KBΪ�������棬��Ȼʣ�µ�16KBһ������Ҳ������ȫû�ã������Գ䵱�Ĵ�������Ļ��������üĴ����ܹ�ʵ�ֲ�������������
���ڲ��м���֮�У�һ�������빲������ͬ����Ҫ�����ǿ�����ͬһ���߳̿��е��߳��ܹ�����Э�����Ӷ��ٽ���Ƭ�����ݹ㷺���ظ����ò�������Ƭ���ͨ�����������洢����ʹ���������CUDAӦ�ó����Ϊ���ܵ���Ҫ�ٳ����ء�
��
�ɶ�̬����Ĺ���ʽһ���������������м���Ч��
��������һ���������������Cypressӵ��8KBx20=160KB��һ�����棬��32KBx20=640KB�ı������ݹ������棬���ж����64KBȫ�����ݹ������档
��GF100ӵ��64KBx16=1MB������һ������+�������棬���ǿ��Ա���̬�Ļ���Ϊ256KBһ������+768KB�������棬����768KBһ������+256KB�������棬�����12KBx16=192KB���������棬���۴��ĸ��������Ƚϣ���Ҫ��Cypressǿ�ܶࡣ

�˴�NVIDIA�����ԵĿɶ�̬����һ��������ƣ�������CPU���涼�����й����Ƚ����������������GPU���м�������ݴ���������ʹ��GPU�Ӵ������������Դ�ڸ߸����ܼ�������ʱ�����ڳ���ƿ�����Ӷ����ӳ��ֲ��ĸ�������������
GPUƪ������ʽ��������������
��������GPU�������沿�ֵ���ƣ���һ�������CPU�dz������ˡ�
��
Cypress�Ķ������棺���Դ�������ķ���ʽ���
������GPU������NVIDIA�ϴ���GT200�Լ�AMD���µ�Cypress���ģ��������涼�����Դ����������һ��ģ������þ�������GPU���Դ����Ӧʱ�䡣�����Դ������һ�㶼��64bitһ�飬Ϊ����ģ�黯��ƣ���˶�������Ҳ������ΪN��������ģ�飬������ͳһ�����塣
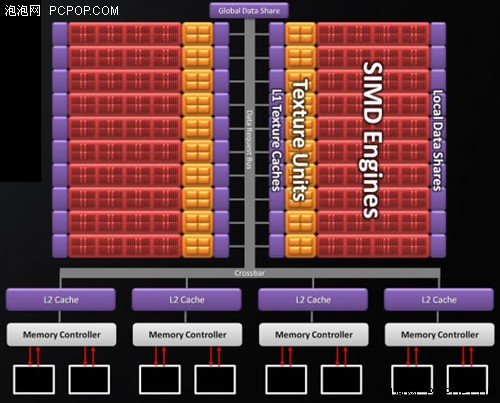
Cypress��L2��Memory Controller
Cypressӵ��4��64bit�Դ��������ÿ���Դ��������128KB�����Ķ������棬�ܼ�512KB���������Ҫ��NVIDIA�ϴ���GT200��һ����
��
GF100�Ķ������棺ͳһ�Ĵ��������ٻ���
��GF100ӵ��һ��768KB����ͳһ�Ķ������ٻ��棬�û������Ϊ�������롢�洢�Լ����������ṩ�����������������GPU���ṩ��Ч�����ٵ����ݹ���������Ч�����������Լ�ϡ�����ݽṹ�����Ȳ�֪�����ݵ�ַ���㷨��Ӳ�����ٻ����ϵ�����������Ϊ���ԡ����ڴ�����������Ҫ���SM���ܶ�ȡ��ͬ�����ݣ��ù�������洢��֮��ľ�����̣��Ӷ������˴���Ч�ʡ�

ͳһ�Ĺ���ʽ����ȵ����Ļ���Ч�ʸ��ߡ��ڶ���ʽ��������У���ʹͬһ�����汻���ָ��Ԥ������Ҳ��ʹ������������δ��ͼ�IJ��֡����ٻ���������ʽ�Զ�����������۴�����GF100��ͳһ����ʽ�������ٻ�����ڲ�ͬ����֮�䶯̬��ƽ�⸺�أ��Ӷ���ֵ����û��档�������ٻ���ȡ����֮ǰGPU�еĶ����������桢ROP�����Լ�Ƭ��FIFO��

GF100�Ļ���ܹ��ø���ˮ��֮����Ը�Ч��ͨ�ţ��������Դ��д����
ͳһ�ĸ��ٻ��滹�ܹ�ȷ���洢�����ճ����˳��ִ�д�ȡָ�������д·�����루����һ��ֻ������·���Լ�һ��ֻдROP·����ʱ�����ܻ������д�����Σ�ա�һ��ͳһ�Ķ�/д·���ܹ�ȷ���������ȷ���У�ͬʱҲ����NVIDIA GPU�ܹ�֧��ͨ��C/C++�������Ҫ���ء�
��ֻ����GT200����������ȣ�GF100�Ķ������ٻ�����ܶ�����д��
��������ȫһ�µġ�NVIDIA������һ�������㷨��������������е����ݣ������㷨�����˸��ּ�飬�ɰ���ȷ������������ܹ�פ���ڸ��ٻ��浱�С�
��
GF100����ʽ�������濰�ȿ��2��
���Կ�����ATI��һ�������涼����ȫ��ɢ�ģ�Ϊ��Э��һ��������֮������ݽ�����ATI���������һ����ȫ�ֹ�����64KB���ݻ��档
��GF100��һ��������Ը�������̬��Ϊ�����������һ���������ϴ���������Ӷ��������ݴ���������������Ǵ�����һ��ʽ��ƣ����߳�����һ���������Ҳ�������ʱ������ֱ�Ӵӡ��������Ķ�����������ȡ�����������������붨ַʱ�䣬������ƿ����
���ڶ���ʽ�����빲��ʽ�����Ч�������ܣ�������ԣ���ҿɲ���CPU�ķ�չ������֪һ����
���ƣ��칹����CPUǿ������GPU�ӹܸ���
��
CPU��չ���ƣ����ϵ����Ϲ���ģ��
ͨ��ǰ����ϸ�Ľ������ǿ��Է��֣�CPU�ķ�չ���ƾ��Dz���ȥ���ϸ���Ĺ��ܺ�ģ�飬��Э�������������桢�ٵ��ڴ�����������������š�
ĿǰAMD��Intel����������CPU���Ѿ��������ڴ��������Intel���µ�Lynnfield��Core i7 8XX��i5 7XX���Ѿ������˰���PCIE���������ڵ��������ţ���Clarkdale��Core i5 6XX��i3 5XX�����ǽ�GPUҲ�����˽�ȥ��
��
GPU��չ���ƣ����ϵIJ�ʳCPU����
����GPU����ij����������˵������������һ��Э����������Ҫ����ͼ����Ƶ��3D���١�֮������ô������û�б�CPU�����ϣ�����ΪGPUʵ��̫�����ˣ������е����칤�����ƣ�CPU������ȥ����һ�ű�������ģ��Ҫ��ܶ��GPU��������ֻ������һ�������еͶ˵�GPU���������IJ�Ʒֻ�ܶ�λ���ż�����������Ϸ��Һ����ܼ������Ҫ��
GPU�ӵ�������һ���������������ڲ��ϲ�ʳ��ԭ������CPU�Ĺ��ܣ�����˵�ǰ���CPU������ȥ������ЩCPU�����ó����������ʼ��T&L(����ת�����Դ)��VCD\DVD\HD\BD��Ƶ���롢�������١�������ɫ��������δ����GPU������һ��CPU����Ҫ�Ĺ��ܡ������м��㡢�߾��ȸ������㡣
��
GPUǰ;�ƽ������������δ��
����֪����CPU��һ�����ϵľ���ר���������ٸ��������Э���������˺�����SSEָ�Ҳ����Ϊ�˼�ǿCPU��SIMD(��ָ���������)�����������ܡ���GPU���һ��ʼ�ͱ���Ƴ�Ϊ��SIMD�ܹ�(����CypressҲ�������ּܹ�)��ӵ�пֲ��������������Ĵ�����������GPU�ĸ��������������Ǵﵽ���CPU�ļ�ʮ�������ϰٱ���
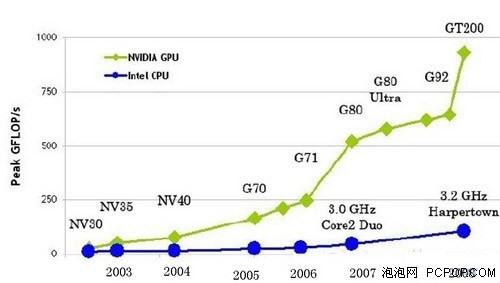
CPU��GPU�ĸ�����������
CPU��Զ���ϲ���GPU�ķ�չ�ٶȣ�������ʺϽ��и����������Ȼ��GPU��CPU�������������Ŀ�Ѿ���ú������壬�������ҵ�綼���뷽�跨�ķ���GPU��DZ�ܣ������еIJ��м�������ת�Ƶ�GPU��������������IntelҲ������GPU������ǰ������������з�GPU��
��ǰ����API�����������ƣ�GPU�ڲ��м��㷽���Ӧ�þٲ�ά�衢��չ������NVIDIA�����ƹ�CUDA�ܹ���ȻС�гɾ͵���������������OpenCL��DirectCompute����API���Ƴ���GPU���м����ǰ;��Ȼ���ʣ���ʱATI��NVIDIA������վ����ͬһ�������ϣ���ô����Ȼ˭�ļܹ����ʺϲ��м��㣬��ô˭���ܻ�ø�ǿ�����ܺ���Χ��Ӧ�ã�ͨ�����ĵķ������Կ�����ATI�ļܹ���Ȼ��רע�ڴ�ͳ��ͼ����Ⱦ�������ʺϲ��м��㣻��NVIDIA�ļܹ�����ȫ���ͨ�ü���API��ָ��Ż���ƣ�ȷ���ܷ��ӳ��ӽ�����ֵ���Ч�ܣ��ṩ��ǿ�ĸ����������ܣ�
��
CPU���ٹյ㣺ǿ���������ܣ��������㽻��GPU
AMDͬʱӵ��CPU��GPU������AMD�ڼ������������ܹ�����ҵ�磬�����δ����չ�滮�dz�ֵ�ô��˼��������AMD���µIJ�Ʒ·��ͼ����������һ���ĸ߶�CPU����Bulldozer�������������������������ÿһ�ź���ӵ��˫�����������㵥Ԫ����������Ϊ�ǶԳ���ƣ�

AMD��һ�������������ܹ������ǿ���������㵥Ԫ
��һ������ģ�������������������������ģ�ÿһ����ӵ���Լ���ָ����ݻ��棬Ҳ����scheduling/reordering����Ԫ������������������Ԫ���е��κ�һ��������������Ҫǿ��Phenom II�����е�����������Ԫ��Intel��Core���������������߸��㣬��������ͳһ��scheduler�����ȣ��ɷ�ָ���AMD�Ĺ���ʹ�ö�������������scheduler��
��AMD¶��Ŀǰ�����ڷ������ϵ�80%�IJ������Ǵ�����������������AMD��һ��CPU�����ǿ���������㵥Ԫ�����Ӹ������㵥Ԫ�����ң�����CPU��GPU�칹����Ӧ��Խ��Խ�࣬GPU����Խ��Խ��ĸ���������IJ�����Ԥ��δ��3-5���ʱ���ڣ����и������㶼���ύ�����ó������������GPU����Ҳ������������ǿ�������������Ŀ�ġ�
��Ȼ��AMD��Intel�����Ƴ�CPU����GPU�IJ�Ʒ�������ǽ�ˮ����ԭ���Ľ����������Ŀ�IJ�����Ϊ�������Կ���GPU������ͨ�����õ�GPUΪCPU�ṩǿ��ĸ����������������������칤�����ޣ���CPU�����ϵ�GPU���Ǽ��ɿ������еͶˣ�ֻ�������������������Ҫ��ǿ�����Ϸ���ܺͲ��м������ܵĻ���רΪ�����������Ƶ���һ���ܹ���GPU��Ʒ�����������ǵ�ѡ��
����˵��CPU��GPU��˭Ҳ������ȡ��˭��˫���ǻ����Ĺ�ϵ��ֻ��CPU��GPUЭͬ���㣬����ȥ�������ó��������ܷ��ӳ��������ǿ��Ч�ܡ�CPU������GPU�ģ��������еͶ˲�Ʒ��GPU��ȡ��CPU���и�������ģ�������Ȼ��ҪCPU�����в���ϵͳ�����������������ֻ�е����칤�շ��ﵽһ���̶�ʱ���п��ܽ�CPU��GPU�����ں���һ�𣬵�ʱ����CPU����GPU����GPU����CPU������˵����˭��˭�����Ѿ�����Ҫ�ˡ���




 �Ƽ���
����Ϣ
��������
�һط�ʽ
�Ƽ���
����Ϣ
��������
�һط�ʽ
 �ֻ���
�������
��ҳ
�ֻ���
�������
��ҳ
 �ֻ���
������
����
�ҵ�
����
�ֻ���
������
����
�ҵ�
����
 ����VIP
����VIP
 ���߿ͷ�(1)
���߿ͷ�(1)
